


Summarizing long documents with AI
Is AI Smart Enough to Summarize Your 500-Page eBook?

In my experience working on vault.pash.city, over 40% of user queries have been geared toward document summarization. Thousands of people often upload a document and have one straightforward yet challenging request: “Can you summarize this?”
The popularity of this use-case led me to develop a new mini-app: summarize.wtf

Summarize.wtf allows you to upload any document—be it PDF, txt, ePub, or Docx—and generate summaries of varying lengths: short (tweet-length), medium (one paragraph), or long (detailed and comprehensive). Let’s explore how it works.
Short Documents are Easy
For documents that are short enough to fit within an LLM's (Large Language Model) long context window— ranging from 16,000 to 32,000 tokens, or about 32-64 pages —the task is straightforward. You feed the entire document to the LLM, and out comes a neatly packed summary.
However, what happens when the document in question is an entire eBook or a 100+ page PDF that exceeds the model's context window?

Long Documents: It Gets Complicated
For big documents that can't fit into a long context window, you need to figure out how to compress the meaning of the entire document to fit within the context limit.
1. Cutting Out the Middle
Some services take a naive approach by using only the beginning and the end of the document to generate a summary. While this might work for research papers that have an abstract upfront, the method is flawed. It risks:
Missing critical information tucked away in the body of the document.
Lack of contextual flow leading to incoherent summaries.
Misrepresenting the core arguments or plot of the document.
2. Importance-By-Word-Occurrence
Techniques like TextRank were popular in the pre-LLM world. This approach splits up the document into sentences and scores each one based on the frequency of key terms or “important words”. Then the “most important” sentences are stuffed into the long context window and the hope is that those sentences are cohesive enough to generate a reasonable summary. While this may work occasionally, this approach has several pitfalls:
It often misses nuanced or less explicit yet important information.
The isolated important sentences might not make a cohesive summary.
Highly technical or uncommon terms may skew the importance ranking.
3. Map-Reduce
In the post-LLM world, Map-Reduce has become a popular summarization technique. Libraries like LangChain offer this out-of-the-box.
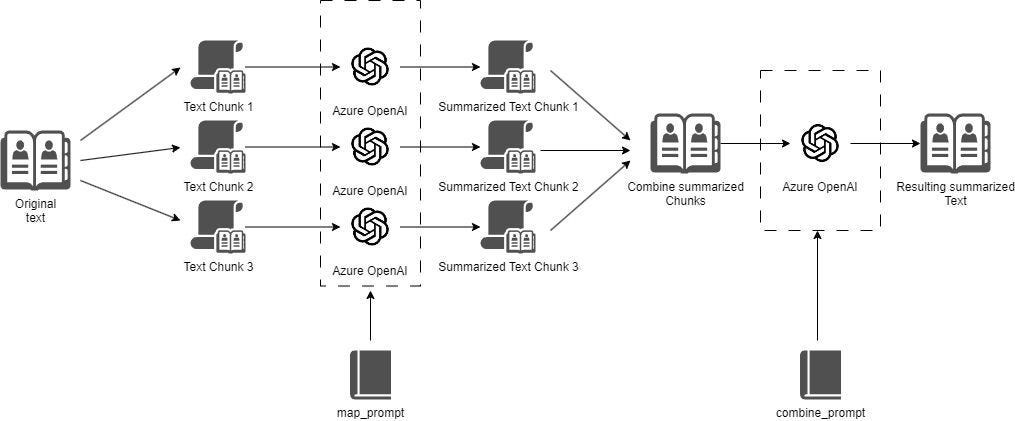
At a basic level, Map-Reduce is a two-step process:
First, individual sections of the document are summarized (Map),
Then, these mini-summaries are combined to form the final summary (Reduce).
This is done over and over until the output summary fits within your desired context length. Although this results in the most inclusive summary, it's computationally expensive and time-consuming: The costs and processing time associated with this step grow super-linearly with the length of the input-document. Thus, Map-Reduce is by far one of the most expensive methods of AI-summarization.
The Optimal Cost-Effective Approach: Break Down the Document into "Key Topics"
Given the constraints and complexities of the above methods, I've found that the most effective approach is to split the document into paragraphs, or chunks (this technique is discussed in my previous article), and generating vector embeddings for each chunk.

The result is that the meaning of each of these chunks (or paragraphs) is captured in a multi-dimensional vector space.
Paragraphs talking about similar things will be “closer” to each other in this meaning-space, forming an embeddings “cluster”. So if the introduction of your document is talking about one thing, and another section of the document is talking about something else, they will fall into distinct meaning-clusters.

You can then use a clustering algorithm like K-means to identify these clusters and take the center point (or collection of points) from each cluster to extract the representative chunk that represents the “average meaning” of that topic cluster.
In effect, this strategy identifies “key topics” within the document and assembles them to create a context-rich summary. This technique is the backbone of both vault.pash.city and summarize.wtf.

To summarize (pun intended):
The document is first split into sections.
Each section is vectorized.
K-means clustering identifies key topic clusters within these vectors.
The representative vectors of these clusters are sequentially sorted by where they appear in the document and fed into an LLM to generate a cohesive and comprehensive summary.
This approach is not only cost-effective but also ensures a high-quality summary while minimizing processing time. Unlike in Map-Reduce, only one call is made to the LLM to generate the final summary, saving you a lot of money. Documents of any length—from brief articles to epics like the Odyssey—are fair game.
Summing it Up
Summarization is a complex task, especially when the document exceeds the token limits of current LLMs. From naive beginnings-and-ends approaches to computationally expensive Map-Reduce techniques, various methods have tried to tackle this challenge with varying levels of success.
The key is to strike a balance between comprehensiveness, accuracy, cost, and computational efficiency. Vector clustering combined with K-means offers this balance, making it the go-to choice for vault.pash.city and summarize.wtf.
If you haven't tried it yet, I invite you to test out these summarization capabilities at summarize.wtf. Whether you're dealing with a two-page article or a sprawling novel, this approach gives you a crisp, coherent, and insightful summary.
Until next time!
Hi ! Have you open sourced your code ? It seems very nice, and I would be keen on having a look!
Cheers
Is the choice of k in kmeans data-dependent or fixed?