
Understanding Long Documents with AI
Are long context windows superior to vector embeddings when analyzing long documents?

While working on vault.pash.city, I came across tens of thousands of users interested in leveraging AI to better understand and extract information from their documents. I found that people were using Vault for all kinds of use-cases – students analyzing research papers, readers asking questions about ebooks, business owners digesting troves of product reviews, and even DnD Dungeon Masters processing player stats. Across all of these widely differing use-cases, I noticed there are two key patterns:
People asking specific, pin-point questions about information contained within their documents, or searching for relevant examples within their documents.
“What are the late payment fees mentioned in the uploaded credit card policy document?”
“What are five examples of gods intervening in Odysseus’s affairs?“
“What is the contract’s end date?”
People asking overarching questions that require a “comprehensive” understanding of an entire body of work.
“Can you summarize this document?”
“How does Joe’s character develop over the course of the entire book?”
“Does this proposal meet all of the requirements (attached to prompt)?”
I started Vault as an open-source project, initially focusing on vector embeddings to give Large Language Models (LLMs) long-term memory. As more people used Vault, I noticed that vector embeddings, while certainly helpful, are not well suited for the second use-case outlined above.

So, I started exploring LLMs with long context windows – like Anthropic’s Claude 100K model. At first, this appeared to be a eureka-tier solution for this problem, at least for documents that fit within these generous context windows. However, as it turns out – this is not always the case.
Key Takeaways
Between employing long context windows vs. a vector embeddings approach to process long documents, there is no one-size-fits-all solution; both strategies have tradeoffs and are best suited for different use-cases.
Expanding the context windows of LLMs might seem beneficial at first glance, but it comes with its own set of drawbacks including increasing costs, latency issues, and potentially decreased quality of responses.
LLMs can struggle to efficiently process relevant information when given very large contexts, especially if crucial information is embedded in the middle of the document. This difficulty intensifies as the context size increases.
Vector embeddings can help optimize the use of LLMs by finding and providing focused, relevant information across a massive knowledge-base, thus increasing the model's efficiency per token; however, vector embeddings fall short when it comes to “comprehensive” understanding of entire documents.

Long Context Windows: “Lost in the Middle”
In the recent Stanford publication "Lost in the Middle," Liu's team demonstrated that modern LLMs often struggle to mine important details from their context windows, particularly when these details are nestled within the middle segment of the context.
“We find that performance is often highest when relevant information occurs at the beginning or end of the input context, and significantly degrades when models must access relevant information in the middle of long contexts.”
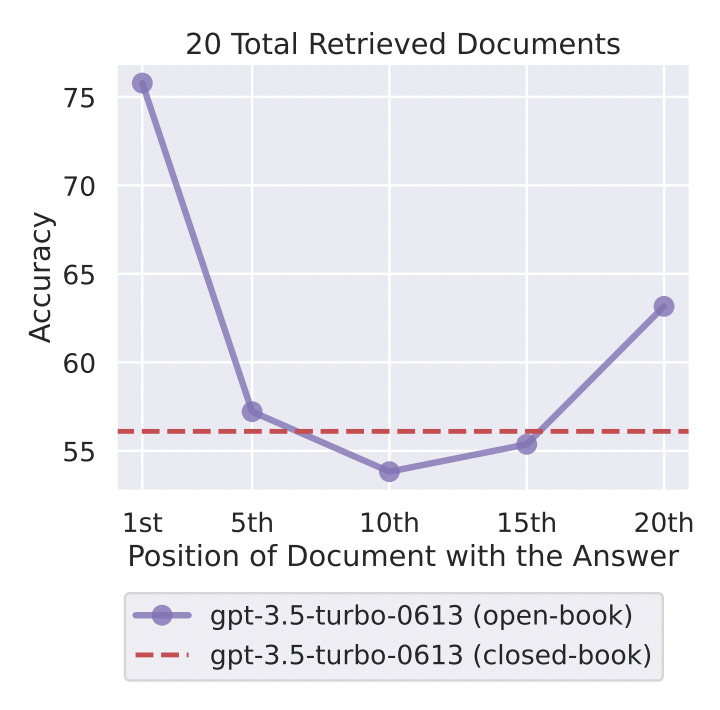
The researchers found that LLMs have a challenging time distinguishing relevant information within lengthy, unstructured contexts - when multiple documents serve as input to the model. They noticed that this issue becomes increasingly pronounced as the size of the context expands.
For instance, a gpt-3.5-turbo-16k model especially designed for extended context experienced nearly a 20% drop in accuracy when dealing with 30 documents as compared to 5.

Pros and Cons of Using Vector Embeddings Databases vs. Long Context Windows
While it may initially seem beneficial to feed all your data to a large language model via an expanded context window, this "context stuffing" approach is very costly and often underperforms expectations.
That being said, if you’re looking for a comprehensive understanding of a particular document that happens to be shorter than the context window, a long context window will be more suited than vector embeddings for this use-case.
On the other hand, if you’re searching for highly specific information nested within a document – or for that matter, thousands of documents – a vector approach will be more accurate and cost-effective.
Pros of Long Context Windows
“Key Takeaway” Questions: When asking overarching, comprehensive questions about documents that fit entirely within the context window, using an LLM with a long context window is superior to employing vector embeddings:
“Can you summarize the key points this document?”
“How does Joe’s character develop over the course of the entire book?”
“Does this proposal meet all of the requirements (pasted below)?”
Comprehensive understanding: If you are asking questions about a specific, known document, larger context windows can potentially provide LLMs with more comprehensive information, which could lead to better quality responses.
Cons of Long Context Windows
Decreased accuracy: As per the recent paper from Stanford titled "Lost in the Middle," LLMs often struggle with extracting valuable information from their context window and pay significantly less attention to the middle of the context as opposed to the beginning and the end.
Impossible to deal with thousands of documents: While Anthropic’s 100K context window and OpenAI’s 32K GPT-4 model offer impressively long context windows, 100K tokens is not much in the grand scheme of things – you can feed about 400 pages of text into a prompt before you hit the token limit.
Increasing costs: As the size of the context window increases, so does the computational requirement and thus the cost.
Latency issues: The time taken to process a large context window can be significant, which could be unacceptable for real-time applications.
Pros of Vector Databases
Needle-in-a-Haystack questions: the vector approach will work well to extract relevant information at large scale – like finding highly specific information within a large knowledge-base, or finding relevant examples within your context to what you’re searching for – If you’re searching for something very specific within a massive trove of documents, vector embeddings are superior:
“How many employees in the instructional design team did Southeast Public University have?”
“What are five examples of gods intervening in Odysseus’s affairs?”
“What is the contract’s end date?”
Cost-effective: The cost of using vector databases does not increase linearly with the volume of data, unlike large context windows.
Flexibility: The parameters of vector databases are explicitly adjustable, offering opportunities for further optimization.
Can handle massive quantities of documents: Vector embeddings can manage and process a vast amount of information, allowing them to swiftly locate precise data even when dealing with thousands or even millions of documents. This makes them an excellent choice for tasks involving extensive corpora or broad knowledge bases – anything from businesses with thousands of financial documents to journalists with rich catalogs of previous articles to refer back to.
Cons of Vector Databases
Non-Comprehensive Understanding: This approach falls short when you’re asking overarching questions like “can you summarize this document?” or “how does this character develop over the course of the entire book?”.
Complexity: The usage and optimization of vector databases require a certain level of technical understanding and expertise. Deciding how you “chunk” documents effectively (how you slice up documents into bite-size 300-500 token segments) can be challenging. You will need to tailor your chunking algorithm to different types of documents (e.g. books vs research papers vs. financial documents).
Hybrid Approach
Given these tradeoffs between long context windows and vector embeddings, it can be prudent to use a hybrid approach to maximize the strengths of each technology, i.e. finding most relevant documents with the help of a vector database, then passing those docs in their entirety into a long context window along with your prompt. This is ideal for use-cases where you don’t know which document contains the information you care about, but you also need a full, comprehensive understanding of the document once you find it.
Often times, a hybrid approach is best suited for information retrieval from a massive knowledge base – commonly employed for troves of business documents or large bodies of work.

In Summary
To sum it all up, Large Language Models and vector embeddings each have their own strengths and weaknesses. There's no one-size-fits-all solution - long context windows may struggle with massive datasets, while vector embeddings may lack depth of understanding. It's all about choosing the right tool for the job, considering both the nature of your data and the questions you're asking.