


Navigating the New OpenAI Update
Should you jump to use OpenAI's Knowledge Retrieval & Assistants APIs?

OpenAI recently unveiled big updates to their API. A number of folks have asked me about the practical implications of these changes, especially when it comes to managing dialogues with the OpenAI Assistants API and using the OpenAI’s Knowledge Retrieval capabilities for content extraction.

A common question I’ve encountered is “Should my business integrate these enhanced capabilities directly, or should we invest in developing a custom solution tailored to our specific needs ?”
OpenAI Assistants
To quickly build a simple chat interface, the Assistants API is your go-to. But if you're crafting something that needs to stitch conversations over time or delve deep into user interactions, you might need to look beyond.
 | OpenAI Cookbook")
Pros:
Simplicity: The OpenAI Assistants API reduces the complexity significantly. There's no need to store conversation data – just session IDs. Plus, scalability and maintenance? OpenAI's got that covered.
Privacy and Security: Since the conversation history evaporates after the session, privacy concerns take a back seat. But remember, if you're storing other data (which you likely will anyway), compliance still knocks on your door.
Deep functionality, out-of-the-box: With tools like Knowledge Retrieval, Code Interpreter, and Function Calling integrated into the API, you're not only handling conversations but also enriching them with a deeper level of interaction and information retrieval.
Cons:
Limited control over context: You can’t cherry-pick which part of the conversation to focus on.
The API decides for you, potentially skipping over crucial early messages.
If the conversation is too long, OpenAI will naively throw out older messages in favor of newer ones.
You are entirely at the whim of your Assistant. You have no control over how many tokens it decides to use, and it tends to max out its token window by default. Assistants get expensive, fast.
Currently, the Assistant will include the maximum number of messages that fit in the context length.
Session Amnesia: Once a session wraps up, so does the context. This can be a hurdle if you need long-term memory or follow-up across multiple sessions.
Lack of Streaming Capability (for now): Although the OpenAI team said that streamable responses are a high-priority feature, the Assistants API currently does not support streaming responses, forcing users to wait for the entire response to be generated, leading to higher latency and clunky UX.
Fixed Context Window and Model: The Assistants API doesn't allow for dynamic adjustments to the context window size or model during interactions; these settings are fixed upon creation of the assistant.
Example: For Vault, I’m using a custom, Completions-based pipeline instead of Assistants, and I have full control over which context window I’m using for different kinds of queries. So if users are asking in-depth, comprehensive questions or asking for summaries, I swap to a 32k or 128k GPT4 model, depending on the context retrieved. This is simply not possible to do with the Assistants API currently.
No Temperature Control: For RAG based applications, this is a crucial option that’s simply not available in the Assistants API currently. This means that you have no control over how creative or unpredictable the responses can be.
Bottom Line: Considering that you’ll likely need to store the entire conversation anyway (so that it persists in the UI across different devices), using the Assistant API over the Chat Completions API starts making less sense. The main benefit I can see is you get access to Assistant Tools (which cannot be understated as a huge plus), and you don’t have to worry about deciding which parts of the conversation to include – but this is a double edged sword.
Expensive: As discussed in the OpenAI forum, people have noticed that adding messages to a thread incrementally increases the context, often hitting the maximum token limit. This lack of control over the token window per run, combined with the inability to specify or limit the context sent, can make the Assistants API costly for intensive projects. Users are exploring alternatives like using the chat completions endpoint for better control, particularly for functions requiring precise execution.
OpenAI Knowledge Retrieval
For a basic app, the Knowledge Retrieval API is a swift solution, but it might not fit the glove if you’re trying to build a high-quality, tailored experience or if you need to integrate specialized content.

Pros:
Simplicity: Building and maintaining a custom retrieval pipeline? That's a task you can strike off your list with OpenAI's Retrieval API. This results in less work and maintenance for your developers.
Data Privacy is now OpenAI’s responsibility: OpenAI takes the reins of data privacy and security, ensuring compliance and safety.
Cons:
Customization? Limited: OpenAI’s retrieval process won't bend to suit your specific data needs
Example: you won’t be able to pinpoint the exact page where chunks of retrieved text originate in their source documents, let alone extract detailed positional data within PDFs.
This will force you to implement hacky workarounds like searching documents using the chunk text (if you’ve worked with PDFs before you’ll understand what kind of headache this can be).
No control over which chunks are selected
Example: Imagine a user asks for details about a specific event in a historical document. You might want the AI to focus on a particular section that thoroughly covers this event. However, OpenAI might choose a different section that only briefly mentions it, potentially overlooking the depth of information you know exists elsewhere in the document.
No access to vector embeddings
OpenAI storage costs are insane: $0.20/GB/assistant/day
Example: Let's say you’re building an essay-writing co-pilot. An average student uploads 250mb worth of PDF references for each essay they write.
In a single semester, a student will write 10 essays. So, in a year, an average user will write 20 essays, and upload 5GB of references.
In this example, the cost for storage for 10,000 active users will be between
$800/day (if you limit users to only being able to write one essay at a time)
$10,000/day (if users can write up to 10 essays at the same time)
File Size Ceiling: Each file has a 512 MB cap, which is a constraint you wouldn’t face with a custom pipeline.

Bottom Line: The Knowledge Retrieval API is undeniably appealing. However, the trade-offs in customization and control, alongside potential cost implications, can turn out to be significant deterrents.
This is where the concept of a Retrieval Service ‘Middle Layer’ comes into play. Rather than solely relying on the constraints of a pre-packaged API, there's a compelling case for building a customized layer that bridges the gap between OpenAI's technology and your unique application needs.
The Crucial Retrieval Middle Layer
While simplifying your tech stack by directly using OpenAI's Retrieval API might be tempting, it will be crucial to have a wrapper layer that adapts to ongoing changes and integrates best practices.
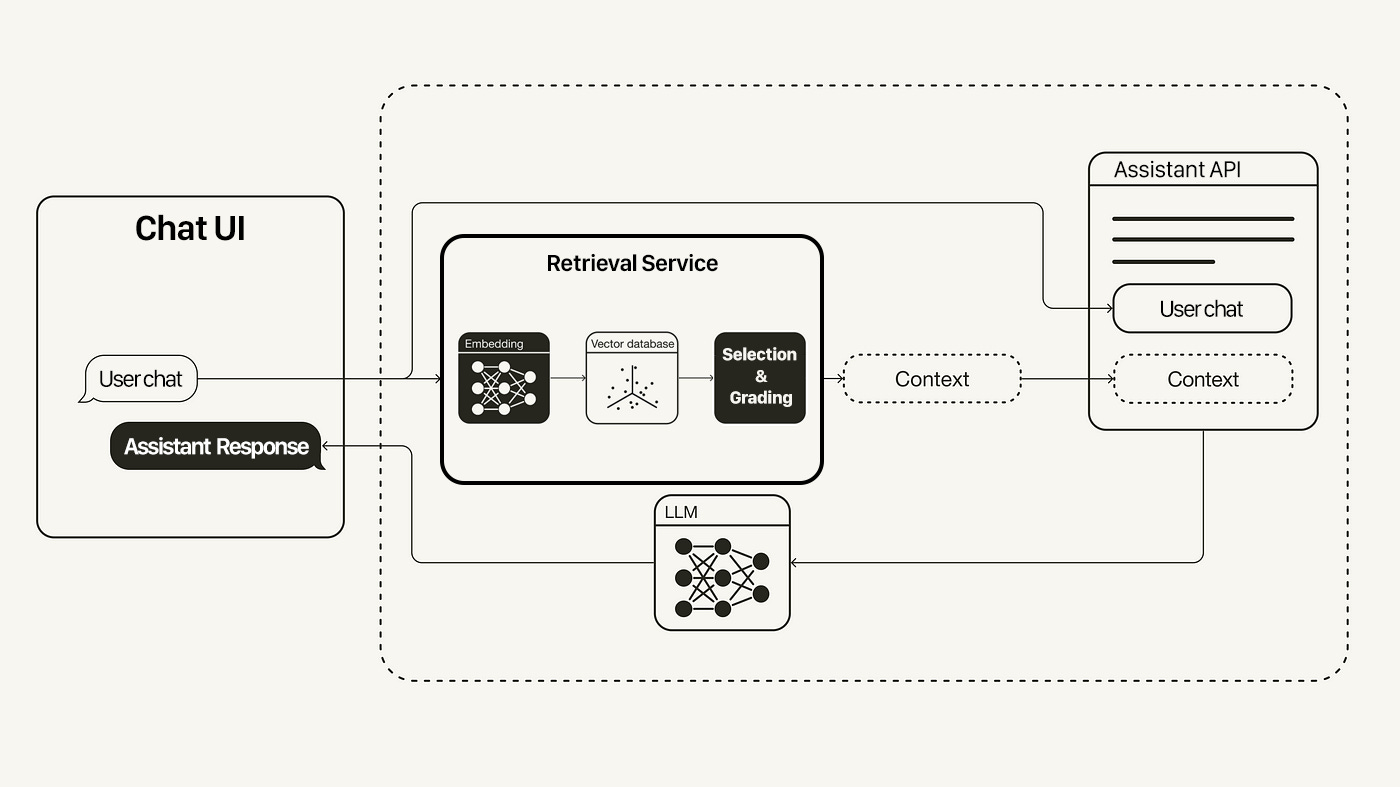
Future-Proofing the Solution: AI and machine learning technologies, including those offered by OpenAI, are evolving rapidly. A middle layer allows for flexibility and adaptability in integrating these changing technologies without overhauling the core application each time.
A custom middle layer can also potentially integrate multiple AI services (from OpenAI and others) as needed, offering a more versatile solution
Best Practices and Stability: An intermediary layer, managed by someone with expertise in the latest AI techniques and best practices, will significantly enhance the stability and performance.
Key Features Not Possible Without It: Certain features like page number handling in RAG API or the extraction of meaning clusters using techniques like K-means (for comprehensive Q&A or summarization) are not provided directly by OpenAI. A middle layer can add these functionalities, thereby extending the capabilities of the basic API.
Customization and Optimization: A custom retrieval process is essential to enable an experience that stands out from the competition. The way references are graded and selected before being incorporated into the drafting process is vital for the quality of your responses.
Bottom Line
The decision between leveraging OpenAI's ready-to-use APIs and constructing a custom solution is more than just a technical choice—it's a strategic one, shaping the future trajectory of your product or service.
After looking into this deeply, I’d say you can strike a strong balance by leveraging Assistants for their powerful function-calling decision-making process, while mitigating downfalls by storing and managing user conversations in your own database. You can then hook up your own retrieval service as yet another function available to your assistant. This provides a foundation for greater flexibility, deeper integration, and the ability to stay agile in a rapidly advancing landscape.
Until next time!