
Fast Apply Models are Already Dead
Another clever workaround engineers will defend long after frontier models make them obsolete.

In July 2024, Cursor released a feature called Instant Apply, built around a fine-tuned “Fast Apply” model. At the time, frontier models like GPT 4o exhibited laziness, inaccuracy, and high latency when handling large code edits, necessitating a specialized model to achieve accurate edits in long files.
Back then, you had two options when it came to editing files.
You could regenerate the entire file from scratch, which burned tokens, erased comments, broke formatting, and often introduced subtle problems in unrelated parts of your files. Worse, if your file was longer than the maximum token output of these models, you would be left with an incomplete file.
Alternatively, you could ask the model to output a targeted search & replace json that you could then algorithmically apply (using string matching) to your file. This was a promising option, and even worked ~75% of the time. But when it failed, it was particularly painful from a UX perspective…
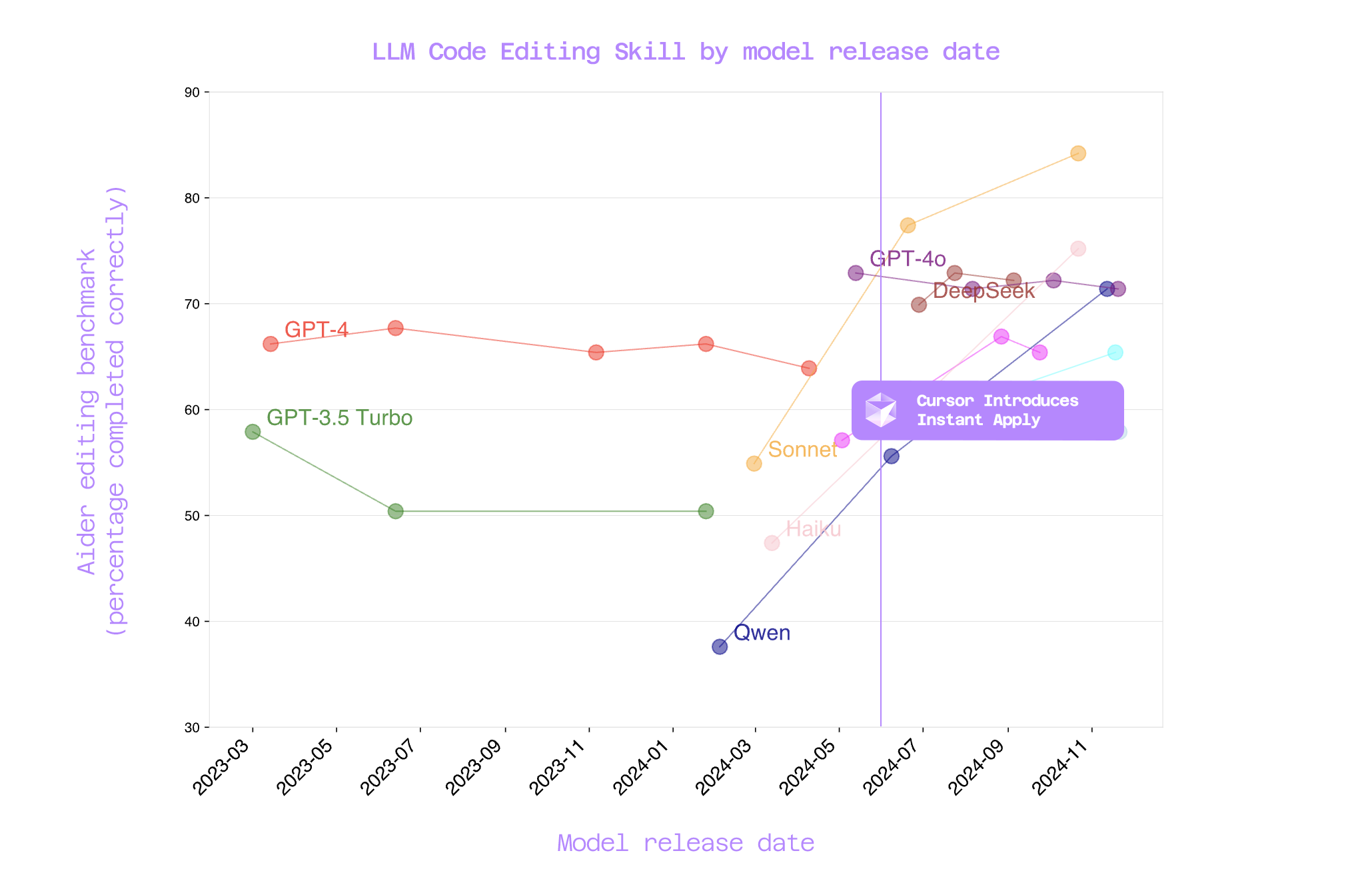
With Cursor’s Fast Apply model, a third option was introduced. I won’t go into the details of speculative decoding and full-file rewrite conditioning (you can check out an web archived version of Cursor’s blog post that they curiously deleted), but it was clever workaround that resulted in higher accuracy on real-world code edits, especially in long or structurally complex files.

Instead of asking the model to be precise, Cursor let it be vague. The frontier model could spit out incomplete or fuzzy edits, with lazy comments like “rest of the imports here” that we’re all reluctantly familiar with.
Cursor would then hand that lazy snippet (as well as the full unedited file) off to a separate, dedicated model trained to rewrite the entire file correctly. This “apply model” didn’t need to reason about what to change, only how to stitch those changes into place.
In theory, this split the problem in two: thinking and doing. In practice, it introduced a brittle layer of its own, one that tried to mask upstream laziness with downstream guesswork.
“Now success depends on two LLMs not goofing up instead of one.”
– Paul Gauthier’s (Founder of Aider) Github discussions, May 2024
For a while, this was appropriate. But that era is over.
Fast Apply is Engineer Cope
Fast Apply splits the edit into two steps. That means two models, two chances to fail, disjointed UX, and one brittle handoff in between. If the snippet is too lazy or malformed, the apply model guesses.
When Fast Apply fails, it often fails quietly, leaving behind subtly broken logic or malformed code that isn't immediately obvious.
Remember, this isn’t sonnet 4 writing your code anymore. You’re handing off your production code to some dinky, quantized qwen coder model. Probably 7B if we’re being honest.
The apply “succeeds”, it looks like it worked. And you’re left holding the bag.
You’ve now doubled your surface area for failure.
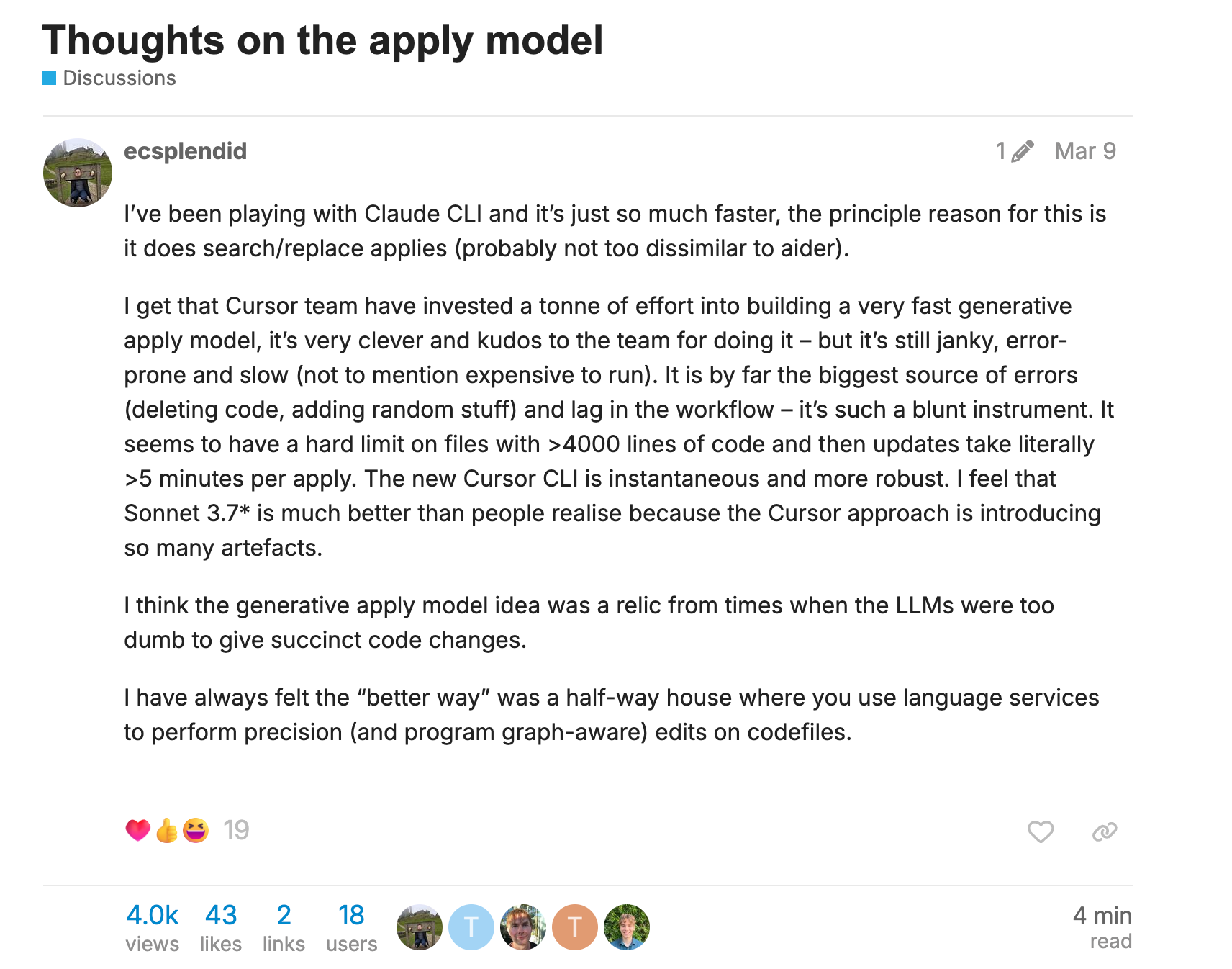
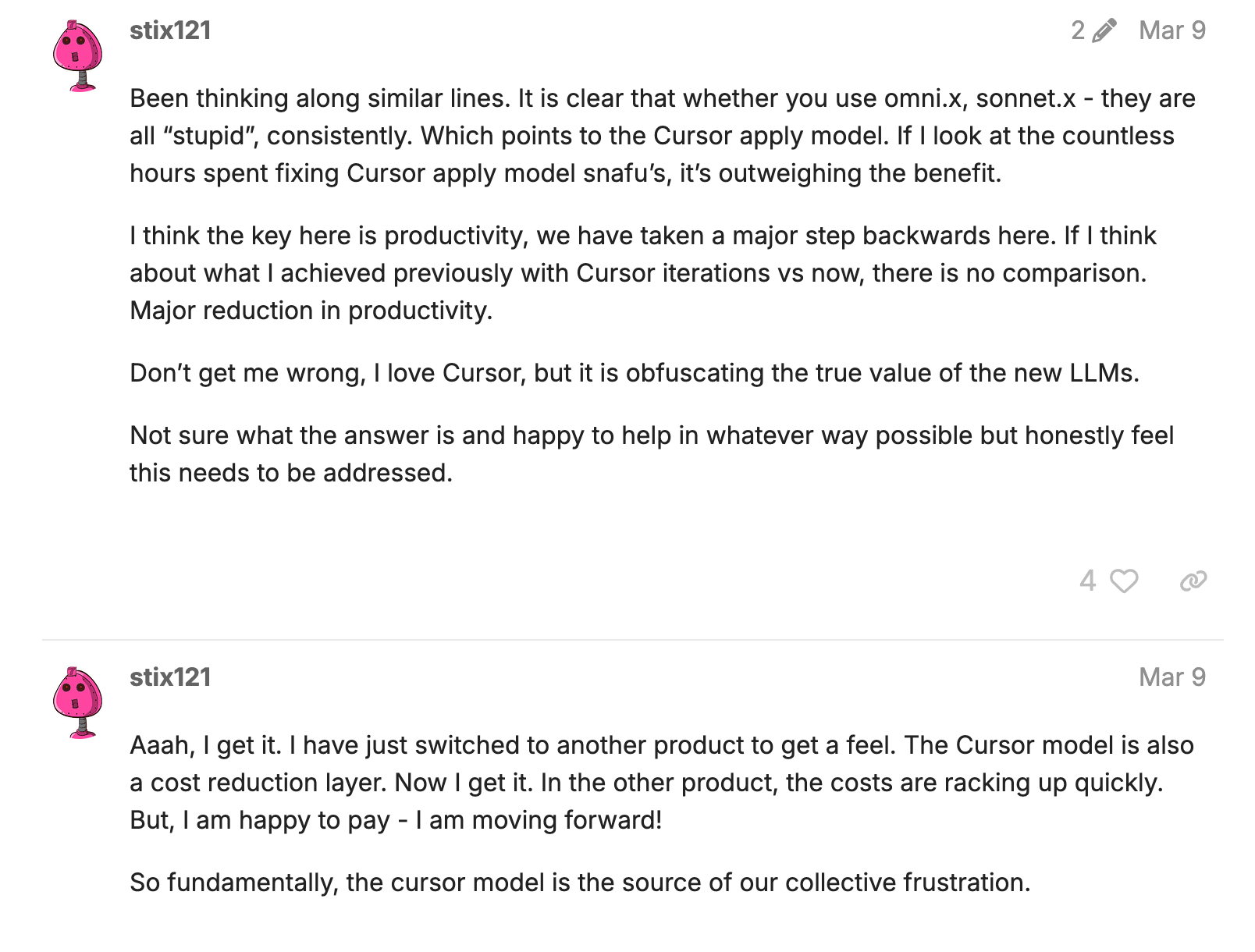
Then come the workarounds. What if your file is longer than the maximum token output of the fast apply model? Now you’re building a workaround for that, where you apply over multiple passes of the file, increasing the surface area for failure even further.
Something else fails? Time to implement a search & replace fallback. To do this, you need to swap in the search&replace tool definition into the system prompt. That breaks prompt caching, leading to two expensive requests, one for the fallback, and one for the rest of the conversation after you swap back to fast apply lazy editing instructions.
Every limitation of the apply model spawns another layer of scaffolding.
This whole process is a form of mental illness. This architecture is clearly flawed in the face of rapidly advancing models, and maintaining it has become a form of delusion or denial.
Anthropic and OpenAI aren’t betting on Fast Apply either
Both teams are chasing top scores on the Aider Polyglot diff editing benchmark, the same benchmark that rewards clean, structured search and replace. OpenAI openly bragged about their diff editing scores in their announcement blog for GPT 4.1.

It’s clear these foundation model labs take diff editing seriously.
Look at their own products. Claude in the browser? Uses search & replace for editing artifacts. Claude Code? Multi-Edit search & replace. ChatGPT’s Canvas feature? Also search & replace. Same goes for OpenAI’s Codex coding agent.
Devin, one of the earliest coding agents, also notably abandoned Fast Apply models:
These systems would still be very faulty. Often times, for example, the small model would misinterpret the instructions of the large model and make an incorrect edit due to the most slight ambiguities in the instructions. Today, the edit decision-making and applying are more often done by a single model in one action.
This isn’t 2024 anymore. The models are strong enough to speak in exact edits. They don’t need a cleanup crew. And they definitely don’t need a dinky little model second-guessing what they meant.
Morph, Relace, and the Temporary Window
Even the founders of Morph LLM and Relace, companies whose entire bread and butter is training these fine-tuned apply models, agree this is a short-lived play. I’ve spoken with Tejas and Preston in the last few weeks. They were frank: Fast Apply has a shelf life. Maybe six months. Maybe less.
They’re betting on a narrow window before base models can speak in structured edits with total precision. The business is to ride that wave. And they’re not wrong. There are still places where Fast Apply might make sense.
If you’re running a $20/mo coding agent and your margins depend on wringing every last token out of inference, sure. If your company is forced into using a small, self-hosted DeepSeek model that isn’t good at search & replace, fine. If you're handicapped by infra constraints or latency requirements that rule out structured search & replace, go for it.
Just don’t confuse that with a long-term bet. It’s a stopgap. A hack for teams who can’t afford precision. If you're building serious software, you shouldn't be duct-taping your code editor together with quantized guesses from a 7B.
The Bitter Lesson
Boris from the Claude Code team, said it best.
“The bitter lesson version of this is we just give the model more responsibility.”
They tried RAG. Indexes. Voyage. Then they threw it all out. Agentic search beat everything.
This is the lesson: clever pipelines are fun. They give you something to build. Something to debug. Something to tweet about. But in the end, the bitter lesson wins. The base model, when strong enough, makes the scaffolding irrelevant.
I hinted at this idea in my previous article about why RAG is a bad idea for coding agents. The application layer is shrinking. The scaffolding, the toolchains, the helper models, the retrieval. All of it is dying.
What used to require pipelines, fallback trees, and quantized edit bots is now a single call to a model that just does the job. The more capable these models get, the more every clever workaround becomes overhead, or worse, a distraction for the model.
The future is not deeper stacks. It is less stack.

Lol, I never said that - Tejas
Companies like Cognition never invested in making fast apply amazing, mostly because there are a ton of edge cases that no sane ML team wants to address.
The compute disparity holds no matter which way you cut the cake - even with a 100% search and replace success rate - you are using 2x the frontier tokens needed, just to position code correctly inside a file. Fundamentally the value of fast apply comes from the fast that placement of this code is too easy of a task for a frontier model. Its hard to get fast apply to 98% accuracy. It took us hundreds of iterations. https://morphllm.com/benchmarks
Models as tool calls isn't a trend, its just how intelligence organizes under the constraint of compute scarcity. Deep research uses o4-mini as a tool. What is called 2 points of failure in reality is just products organizing around the minimum compute needed to do a task to high fidelity.