
A response to everyone bashing evals
A short essay on the broader "evaluations 2.0” movement in AI, how evals and RL environments are converging, and why verifiers have become the meta at frontier model labs.

The emergence of Terminal-Bench and Prime Intellect’s Environments Hub signals a broader “evaluations 2.0” movement in AI: a recognition that to build more intelligent and reliable models, we need a standardized way to define complex, realistic tasks as both yardsticks and ladders. Yardsticks (benchmarks) tell us where current models stand; ladders (training environments) help models climb higher.
In practice, Evals and RL Environments are built from the same ingredients, and are basically interchangeable concepts.
I’m writing this essay to explain in simple, clear terms:
What evals really are at a fundamental level
Why evals, RL environments, and “AI gyms” are actually the same thing (two sides of the same coin)
What verifiers are, why they became the new meta, and how frontier model labs use them to improve model reasoning capabilities
But before I dive in, it’s worth addressing a recent debate that broke out on Twitter:
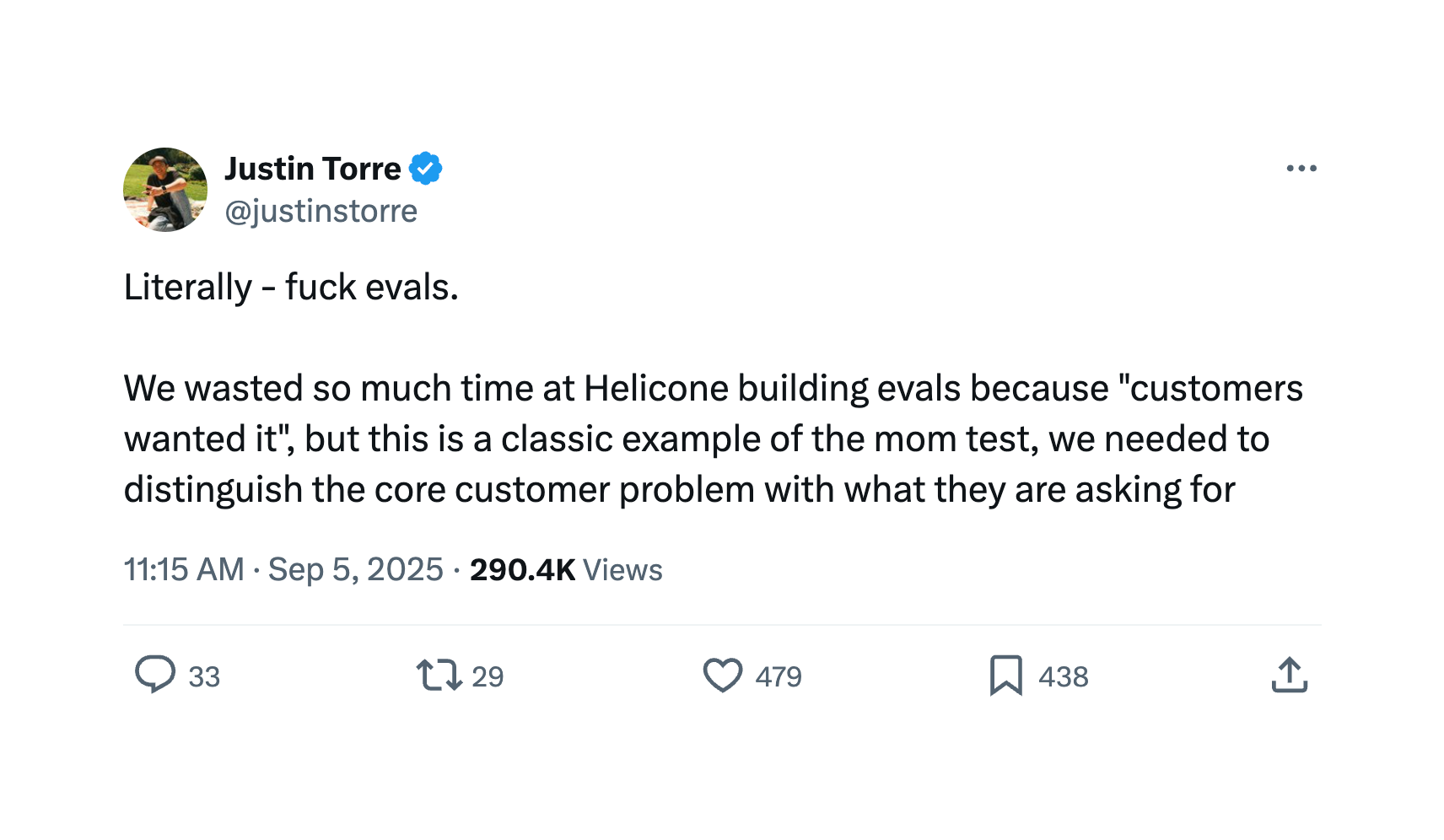
The critique resonated because it contained a kernel of truth about AI product development: why build elaborate eval frameworks when successful products seemed to run on vibes and user feedback?
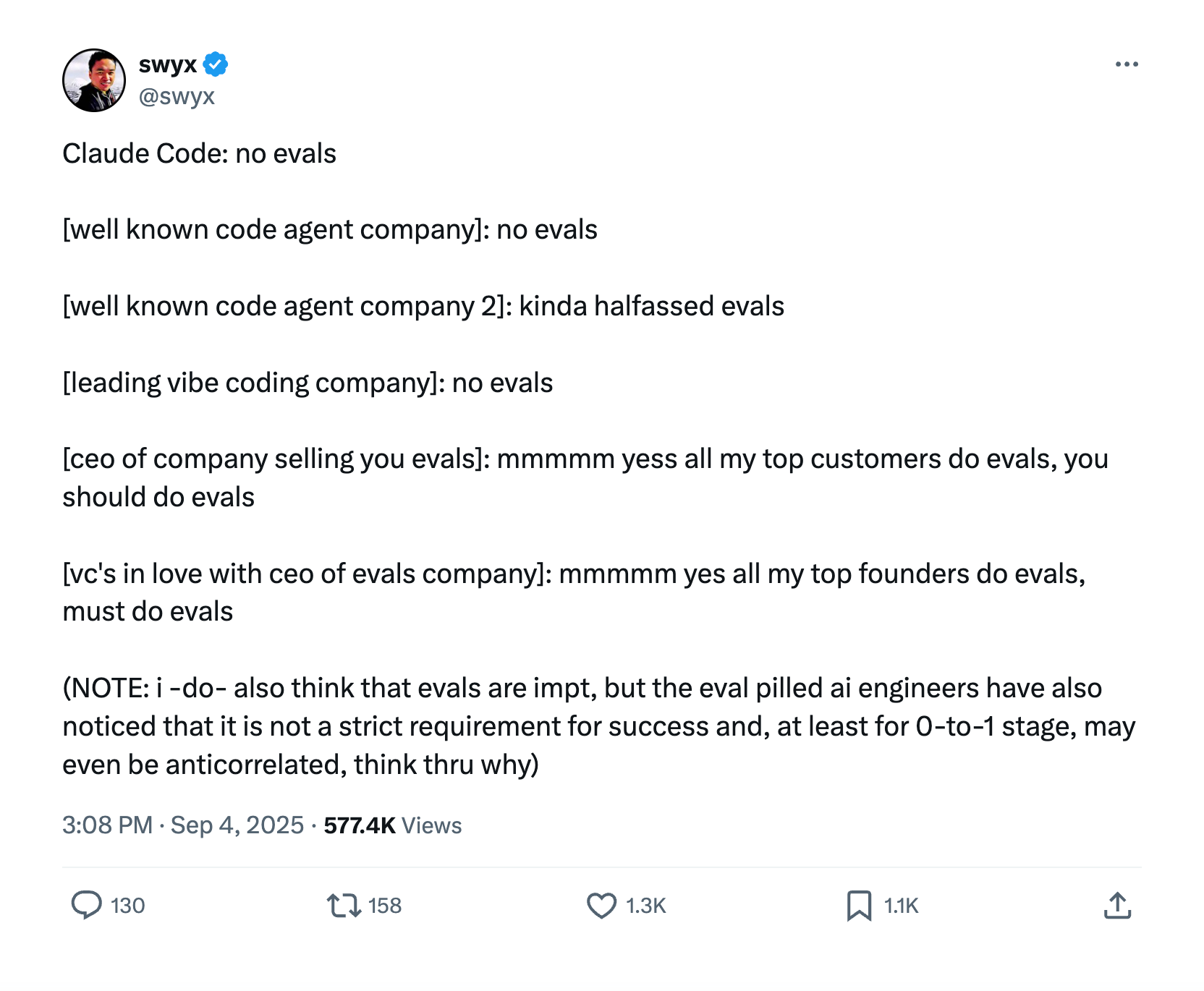
The skepticism was understandable. For example, it was pointed out that “Claude Code doesn’t even do evals.” but this dialectic overlooked a crucial reality — many teams appearing to succeed without evals are either standing on upstream evals or have domain experts implicitly testing the model. In Anthropic’s case, saying Claude Code has “no evals” is a bit misleading because Claude was literally being trained in the coding environment with premium grade SWE-like data.
In
’s words“you can get away without explicit evals if your task is already well-covered by the model’s training”To understand why the anti-eval wave got it wrong, we need to start with the basics:
What is an eval, really?
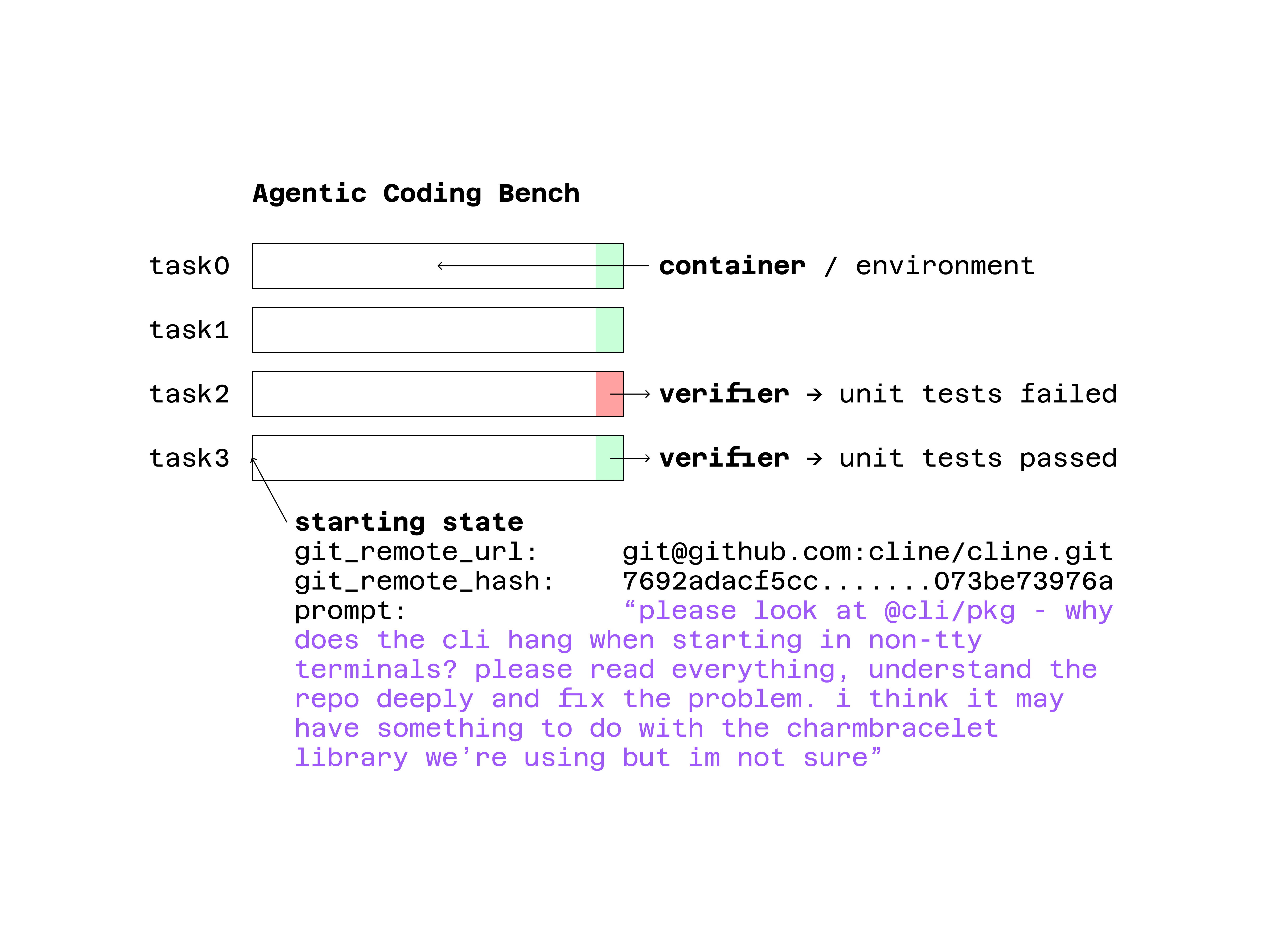
It’s quite simple. Benchmarks consist of three components:
An environment
A starting state
A verifier that checks whether an end state is correct or acceptable
The environment is a little sandbox that gives the LLM an opportunity to actually interact — take actions, see outcomes, and affect the world it’s in. In the case of TerminalBench, it’s just a Docker container that emulates a real developer terminal, complete with files, dependencies, and system tools the model can use.
The starting state defines what the model sees when the task begins — the inputs, context, and initial conditions. In a coding benchmark, this might be the state of a Git repository when the user first started working: the files, the bug report, the failing tests, and the user’s starting prompt that tells the model what needs to be done. It’s the “problem setup,” frozen in time, so every model begins from the same position and the outcome can be compared fairly.
Finally, the verifier is what makes the whole thing measurable. It’s the piece that checks whether the model actually solved the task — the automated judge that turns messy outputs into a simple score or pass/fail signal. That’s why you hear people at labs say “we trained on verifiers”. They’re talking about having a automated way to score model behavior — which then becomes the reward function for RL, or the pass/fail signal for benchmarks.
In other words, verifiers are what make progress measurable — they can be used either to evaluate a model’s performance after the fact, or to train it in real time by converting success into a reward signal that adjusts the model’s weights.
So how are RL environments different?
Well, here’s the thing — they’re not really different at all.
An RL environment is just an eval where the score doesn’t stop at observation. Instead of writing it down in a spreadsheet or leaderboard, you feed it back into the model’s learning loop. The structure — environment, starting state, verifier — is identical. The only distinction is how the reward is used: benchmarks measure performance, RL environments improve it.
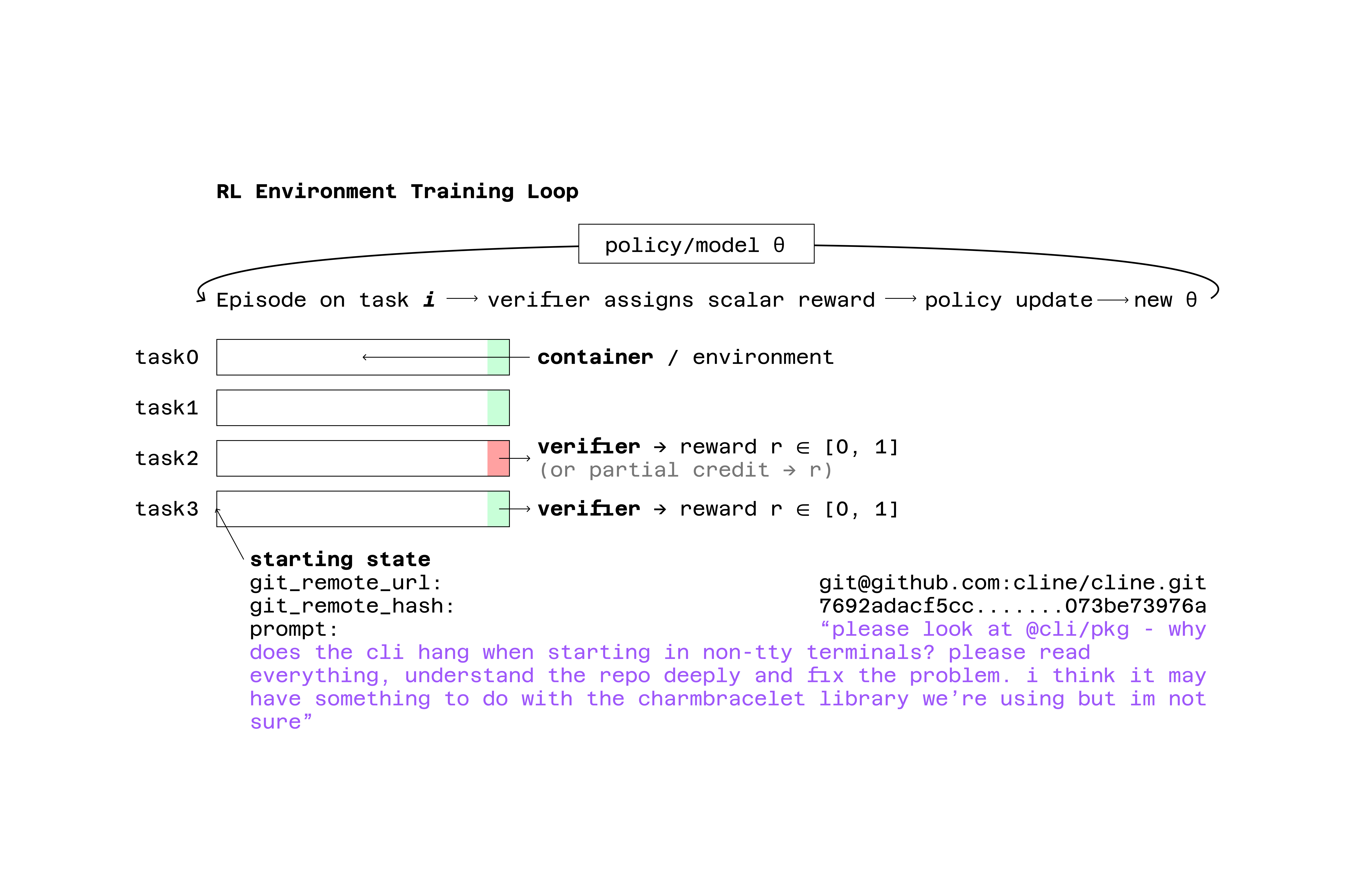
When a model runs inside an RL environment, every episode is an eval in motion. The model interacts with the sandbox, accumulates a reward at the end, and that reward is used to update its weights — typically through some reinforcement learning algorithm like PPO or GRPO.
The exact algorithm or method isn’t really the point; the key idea is that the feedback loop exists. What was once a static evaluation now becomes a live training signal, closing the loop between measuring and improving model behavior.
The rise of verifiers
Verifiers are the quiet engine behind this whole shift. Once labs realized they could automate the judging process, everything changed — suddenly, you didn’t need a human researcher checking outputs by hand or a reward model. You could define correctness in code, run thousands of tasks in parallel, and use that signal not only to measure progress but to improve models directly.
That’s why verifiers have become the new meta at frontier labs.
They blur the line between evaluation and learning: the same script that scores an output for a leaderboard can, with a small tweak, become a reward function inside an RL loop. In practice, this is what allows “benchmarks” to evolve into full AI gyms — places where models don’t just get tested, they get better.
In my previous article, “Coding Agent Companies Are Shortsighted and Blind to Their Role in History”, I wrote about how frontier labs view coding as the first domino in the path toward AGI — the domain that unlocks everything else. It’s no coincidence that the same labs are now pouring their energy into verifier-driven coding environments.
Most of the progress around verifiers has happened in domains like coding or mathematics, because they’re uniquely tractable. In code, success can be defined precisely — the program runs or it doesn’t, the tests pass or they fail. That clarity makes it easy to automate judgment, scale evaluation, and feed the results back into training. It’s no coincidence that every major lab — OpenAI, Anthropic, DeepSeek, Groq, Prime Intellect — is prioritizing code as a proving ground for their reasoning models. Coding is where verifiers are clean, abundant, and unambiguous, making it the perfect engine for rapid capability gains.
Evals are more important than ever
So now that we’ve gotten the fundamentals out of the way, let’s get back to answering the question everyone on Twitter was asking: “Why build elaborate eval frameworks when successful products seem to run on vibes and user feedback?”
Well, because evals are how you make models smarter, directly. Improvements on the application layer are marginal — you can polish prompts, tune UX, and optimize tool schemas all you want, but that doesn’t change what the model is. Evals are how you break past the frontier. They are the force multiplier that accelerates progress more than any prompt tweak or UX improvement combined.
The difference between a product that feels good and a model that gets better is one thing: evals.
The Evaluations 2.0 movement
Benchmarks and RL environments are converging, and together they hold the key to the next leaps in model capability. Two projects in particular have redrawn the boundary between evaluation and training: Terminal-Bench and Prime Intellect’s Environments Hub.
Both share a common goal: to unify how the world defines and exchanges tasks.
They treat evals as primitives. As reusable, composable environments. Standardized interfaces for reasoning. The vision is that anyone can define a complex, realistic task once, publish it with a clear verifier, and every lab or researcher can immediately use it for both evaluation and reinforcement learning.
That’s the real shift behind Evaluations 2.0: from bespoke internal tests to interoperable ecosystems of environments and verifiers. Terminal-Bench gives us the blueprint for realistic, high-fidelity tasks in Dockerized sandboxes. Prime Intellect extends that blueprint into an open-source network of reward-bearing environments. Together, they’re building a shared foundation where benchmarks and training loops speak the same language.
Terminal-Bench started with a focus on evaluation-first (one-shot agent attempts on static tasks, graded pass/fail), whereas Environments Hub is training-first (ongoing interaction with a reward signal).
However, the line between these is blurring. Terminal-Bench’s framework is adding support for multi-step rollouts and even RL fine-tuning, while Environments Hub explicitly supports generating eval reports for any environment (you can run a model on an environment for N trials and get success metrics).
In essence, both systems recognize that evaluating models and improving models are two uses of the same resource: a well-defined task environment. As this Hugging Face writeup succinctly puts it,
Training and evaluating Language Models with Reinforcement Learning requires more than static datasets. As we’ve seen, the environments used for both RL training and agentic evaluations are articulated software artifacts, containing data, harnesses, and scoring rules.
In other words, a benchmark is just an environment with a fixed policy (the model) and a score at the end; an RL environment is the same setup used to optimize the model’s policy.
It’s no surprise, then, that the API to define an environment in the Hub (datasets + parser + reward functions) is very similar to the components you need to define a rigorous eval in TerminalBench.
To illustrate this convergence, consider some examples:
Terminal-Bench tasks have unit test scripts that determine success or failure.
In the Environments Hub, those might be implemented as rubric functions (returning 1.0 reward if all tests pass, or partial credit for subtasks).
Terminal-Bench’s secret test set (they plan to develop hidden tasks for competition) parallels how an RL environment can have a validation scenario. And when Terminal-Bench uses an LLM-as-a-judge (planned feature) to grade an output (for tasks where an automated test is hard), it effectively becomes a learned reward model – exactly what RL training might use.
The boundary between “benchmark” and “training environment” is mostly about whether you’re passively measuring a model or actively tuning it.
Both projects seem to acknowledge this and are building towards the full loop. Andy Konwinski (Prime Intellect co-founder) envisions using such tasks for “Reinforcement Fine-Tuning (RFT) and optimizing agent scaffolds” for specific domains, while Terminal-Bench’s Alex Shaw similarly noted that “[a task in TerminalBench] is actually just an RL environment.”
As Andrej Karpathy remarked, “Environments have the property that once the skeleton of the framework is in place, the community/industry can parallelize across many different domains.”
They give the LLM an opportunity to actually interact - take actions, see outcomes, etc. This means you can hope to do a lot better than statistical expert imitation. And they can be used both for model training and evaluation. But just like before, the core problem now is needing a large, diverse, high quality set of environments, as exercises for the LLM to practice against.
Both Terminal-Bench and the Hub aim to lower the friction for this kind of sharing. Terminal-Bench did so by providing a ready-made harness with sandboxed Docker containers (so you can safely let an agent try potentially risky operations). The Hub does so with a unified interface (prime-rl + verifiers) and even hosted evaluation dashboards.
In other words, Benchmarks and RL environments are converging. Terminal-Bench and Prime Intellect’s Environments Hub exemplify this convergence from two directions.
The next frontier: true multi-shot benchmarks
Almost every benchmark today, even the sophisticated ones like Terminal-Bench, are still one-shot. The model receives a static prompt, runs in isolation, and is graded once at the end.
That’s not how the real world works.
In real coding or support tasks, the process is interactive. The user starts with something vague like “this function isn’t working,” “the layout looks wrong,” “my login’s broken” and ideally the agent asks questions, clarifies intent, and adapts to partial feedback and cancels along the way. The dialogue is part of the problem-solving loop.
So far, no benchmark captures this well. There’s no standard way to judge an agent that asks the right clarifying question, gracefully backtracks after a user correction, or explains its reasoning in a way that makes the next step easier for a human collaborator.
In response to this idea, some people have asked whether this would be optimizing for the wrong thing altogether. If the endgame is models that can one-shot everything perfectly, why focus on making them good collaborators?
It’s a valid question. It’s likely that one day we’ll reach that point where human input is obsolete. But intuitively, I think that humans are going to be working alongside AI for the foreseeable future. In the meantime, it would be nice to have models that riff off of you and work better in a collaborative setting with humans.
In order to achieve that, we need to have evals that test for this and can help train models to be better at this. Until we can measure a model’s ability to cooperate, we’ll keep getting systems that pass static tests and stumble the moment a real human enters the loop. For now, RLHF is a decent stop-gap measure to align model behaviors with human preferences.
Enjoyed this Nik! Nice to learn more about how models are improving and what is accelerating this change.